处理编码问题利器之文本编辑器⑵——Vim
本文链接:https://hltj.me/encoding/2013/04/17/vim-deal-encoding.html 。
接上文,跨平台的开源软件 Vim 和 wxMEdit 是我用过的两个最擅长处理编码问题的文本编辑器。
上文说了 wxMEdit

接下来再看 Vim

Vim 是什么
Vim是世界上公认的第二大文本编辑器(第一大是 GNU Emacs;似有“Emacs 是神的编辑器、Vim 是编辑器之神”之说)。很多人会觉得 vim 很不易用,这其中也有一定的误解。
首先需要弄清楚的是 vim 不是 vi。如今的 vim 是 Vi IMproved 的缩写,相对原始 vi 做了相当多的改善,原本 vi 的功能只占它现有功能很少的一部分。
Vim 易用性
Vim 并不像想象中的那么难用,不习惯用“h、j、k、l”移动光标,完全可以用上下左右,甚至 home、end、page up、page down。
如果在 Windows 上安装 vim,按照默认设置,它会生成一个“gVim Easy”,它看起来更像是功能加强版的记事本,可以使用 Ctrl-C、Ctrl-V、Ctrl-Z、Ctrl-A 这些快捷键,也会有菜单、右键菜单、工具栏。 Windows 版 gVim 默认配置也支持这些,差别是默认是普通模式而不是插入模式。
当然要想用到 vim 更多强大功能就需要了解它的普通模式、命令模式乃至可视模式和选择模式了。这样就的确需要了解一定量的命令技巧才行。
Vim 编码识别
Vim 的编码识别是基于配置的,未配置或者按照默认配置可能效果很差,这就是我们用 vim 打开一个常看到一堆乱码的原因之一(另外的原因是上面部分 linux 系统安装的是精简版的 vim,不支持相关特性)。
如果针对特定环境配置得当,它的编码识别准确率甚至高于 universal-chardet(firefox 的编码识别部分,MadEdit 也用它识别编码的,wxMEdit 改用 ICU)、 enca(一个自动编码识别工具)。例如用下列设置:
set fencs=us-ascii,ucs-bom,utf-8,gbk,gb18030,big5,latin1
去识别简体中文为主有少量繁体中文代码的编码比 universal-chardet、enca 都要精准。这里 fencs 设置只是为了说明编码识别举例,一般很少会单独识别 us-ascii,参见我的 vimrc。
如果仍然识别错了,还可以手动指定编码,例如
echo "0: 32 30 30 30 96 32 30 34 39" | xxd -g1 -r > test.txt
vim test.txt
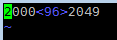
如果 fencs 用上面的设定,这时 vim 会识别编码为 latin1(即 ISO-8859-1),查询 vim 识别到的编码用
:set fenc?
问号可以省略。
但是其中字符 ‘\x96’ 在 ISO-8859-1 中未定义(未定义字符 vim 会用蓝色显示其编码值),可以人为判断它是 windows-1252 编码(可显字符是 latin1 的超集)的。可通过下面命令手动指定为 windows-1252 编码。
:e ++enc=cp1252
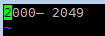
可以看到,该字符是个短线,但是因为我还设置了 ambiwidth=double,所以它显示一个汉字宽,参见 vim 中文文档-ambiwidth、East Asian Width。这也是 vim 具有良好国际化支持的一个特性,该特性对于中日韩用户尤其重要。
Vim 编码转换
类似上面手动指定读取编码的方式,也可以手动指定写入编码,如以 utf-8 编码保存
:w ++enc=utf8 | e
或
:set fenc=utf8 | w
上面两种方式实际上都是两个命令,竖线“|”是 vim 命令的分隔符,相当于 shell 的分号“;”。
不想立即保存,用
:set fenc=utf8
BOM 支持
如上文保存为 utf-8 编码的文件时,默认是没有 BOM 的。如果要让其包含 BOM,需要在保存前 set bomb:
:set bomb | w ++enc=utf8 | e
或
:set bomb fenc=utf8 | w
不想立即保存,用
:set bomb fenc=utf8
即可。
如果对一已有 BOM 的 UTF-x 编码的文件,要去掉其 BOM,用
:set nobomb | w
不想立即保存用
:set nobomb
即可。
查询一个 UTF-x 编码的文件是否有 BOM,用:
:set bomb?
问号不可省略。
有任何问题和建议可以留言,或者发邮件给我 jiaywe[at]gmail.com。

转载请勿修改,并注明作者:灰蓝天际 及许可协议:署名-非商业性使用-禁止演绎。
欢迎关注:
GitHub:hltj 微博:灰蓝天际(@hltj) Twitter:@jywhltj
 |
 |
|---|---|
| 公众号 | 微博 |